Code
# syntax
str_view(data, "string")Ch. 15
key concepts: (escaping, anchoring, character classes, shorthand classes, quantifiers, precedence, and grouping)
fruit contains the names of 80 fruits.words contains 980 common English words.sentences contains 720 short sentences.When a second parameter is supplied, str_view() will show only the elements of the string vector that match, surrounding each match with <>, and, where possible, highlighting the match in blue.
# syntax
str_view(data, "string"). matches any character so j. will match any string that contains j followed by another character.? makes a pattern optional (i.e. it matches 0 or 1 times)+ lets a pattern repeat (i.e. it matches at least once)* lets a pattern be optional or repeat (i.e. it matches any number of times, including 0).^ signals the beginning of a the pattern Note: no surrounding [ ]$ signals the end[ ] and let you match a set of characters, e.g., [abcd] matches “a”, “b”, “c”, or “d”.[^abcd] matches anything except “a”, “b”, “c”, or “d”.| acts as “or”# search for a SINGLE DIGIT number
str_detect(c("a","a1","a123","a1234"),"[0-9]")[1] FALSE TRUE TRUE TRUEstr_view(c("a","a1","a123","a1234"),"[0-9]")[2] │ a<1>
[3] │ a<1><2><3>
[4] │ a<1><2><3><4>str_replace(c("a","a1","a123","a1234"),"[0-9]","x")[1] "a" "ax" "ax23" "ax234"# search for any n-DIGIT number
str_detect(c("a","a1","a123","a1234"),"[0-9]+")[1] FALSE TRUE TRUE TRUEstr_view(c("a","a1","a123","a1234"),"[0-9]+")[2] │ a<1>
[3] │ a<123>
[4] │ a<1234>str_replace(c("a","a1","a123","a1234"),"[0-9]+","x")[1] "a" "ax" "ax" "ax"Now for a TWO digit number
# search for any n-DIGIT number
str_detect(c("a","a1","a123","a1234"),"[0-9]{2}")[1] FALSE FALSE TRUE TRUEstr_view(c("a","a1","a123","a1234"),"[0-9]{2}")[3] │ a<12>3
[4] │ a<12><34>str_replace(c("a","a1","a123","a1234"),"[0-9]{2}","x")[1] "a" "a1" "ax3" "ax34"Now match some date formatting. Work with the flights data.
library(nycflights13)
# grab the unique values
df <- flights |> distinct(year,month,day)
# following the principle that one should avoid typing the same thing 3 times we loop:
for (cn in names(df)){
print(cn)
df <- mutate(df,{{cn}} := as.character(get(cn))) |> glimpse()
}[1] "year"
Rows: 365
Columns: 3
$ year <chr> "2013", "2013", "2013", "2013", "2013", "2013", "2013", "2013", …
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ day <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 1…
[1] "month"
Rows: 365
Columns: 3
$ year <chr> "2013", "2013", "2013", "2013", "2013", "2013", "2013", "2013", …
$ month <chr> "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",…
$ day <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 1…
[1] "day"
Rows: 365
Columns: 3
$ year <chr> "2013", "2013", "2013", "2013", "2013", "2013", "2013", "2013", …
$ month <chr> "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",…
$ day <chr> "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "…# now we join into a date format
df <- df |> mutate(thedate = str_c(day,"_",month,"_",year))
# but that doesn't look very good, let's make everything 2 or 4 digits
# below:
# ^ look at the start of the word
# [0-9] look for any digit
# _ then look for an _
# . this is a metacharacter for any-single-character
# + this repeats the previous token as many times till the end of the string
df <- df |> mutate(nicedate = str_replace(
thedate,"^[0-9]_.+",str_c("0",thedate)))
# this works for some of them but not all:
df |> arrange(df,nicedate)# A tibble: 365 × 5
year month day thedate nicedate
<chr> <chr> <chr> <chr> <chr>
1 2013 1 1 1_1_2013 01_1_2013
2 2013 1 10 10_1_2013 10_1_2013
3 2013 1 11 11_1_2013 11_1_2013
4 2013 1 12 12_1_2013 12_1_2013
5 2013 1 13 13_1_2013 13_1_2013
6 2013 1 14 14_1_2013 14_1_2013
7 2013 1 15 15_1_2013 15_1_2013
8 2013 1 16 16_1_2013 16_1_2013
9 2013 1 17 17_1_2013 17_1_2013
10 2013 1 18 18_1_2013 18_1_2013
# ℹ 355 more rows [1] │ <01_1_>2013
[2] │ <02_1_>2013
[3] │ <03_1_>2013
[4] │ <04_1_>2013
[5] │ <05_1_>2013
[6] │ <06_1_>2013
[7] │ <07_1_>2013
[8] │ <08_1_>2013
[9] │ <09_1_>2013
[10] │ <10_1_>2013
[11] │ <11_1_>2013
[12] │ <12_1_>2013
[13] │ <13_1_>2013
[14] │ <14_1_>2013
[15] │ <15_1_>2013
[16] │ <16_1_>2013
[17] │ <17_1_>2013
[18] │ <18_1_>2013
[19] │ <19_1_>2013
[20] │ <20_1_>2013
... and 253 moreIt's my birthday!.str_detect() returns a logical vector that is TRUE if the pattern matches an element of the character vector and FALSE otherwise:
str_detect(c("a", "b", "c"), "[aeiou]")[1] TRUE FALSE FALSESince str_detect() returns a logical vector of the same length as the initial vector, it pairs well with filter(). For example, this code finds all the most popular names containing a lower-case “x”:
babynames |>
filter(str_detect(name, "x")) |>
count(name, wt = n, sort = TRUE)# A tibble: 974 × 2
name n
<chr> <int>
1 Alexander 665492
2 Alexis 399551
3 Alex 278705
4 Alexandra 232223
5 Max 148787
6 Alexa 123032
7 Maxine 112261
8 Alexandria 97679
9 Maxwell 90486
10 Jaxon 71234
# ℹ 964 more rowsWe can also use str_detect() with summarize() by pairing it with sum() or mean():
babynames |>
group_by(year) |>
summarize(prop_x = mean(str_detect(name, "x"))) |>
ggplot(aes(x = year, y = prop_x)) +
geom_line()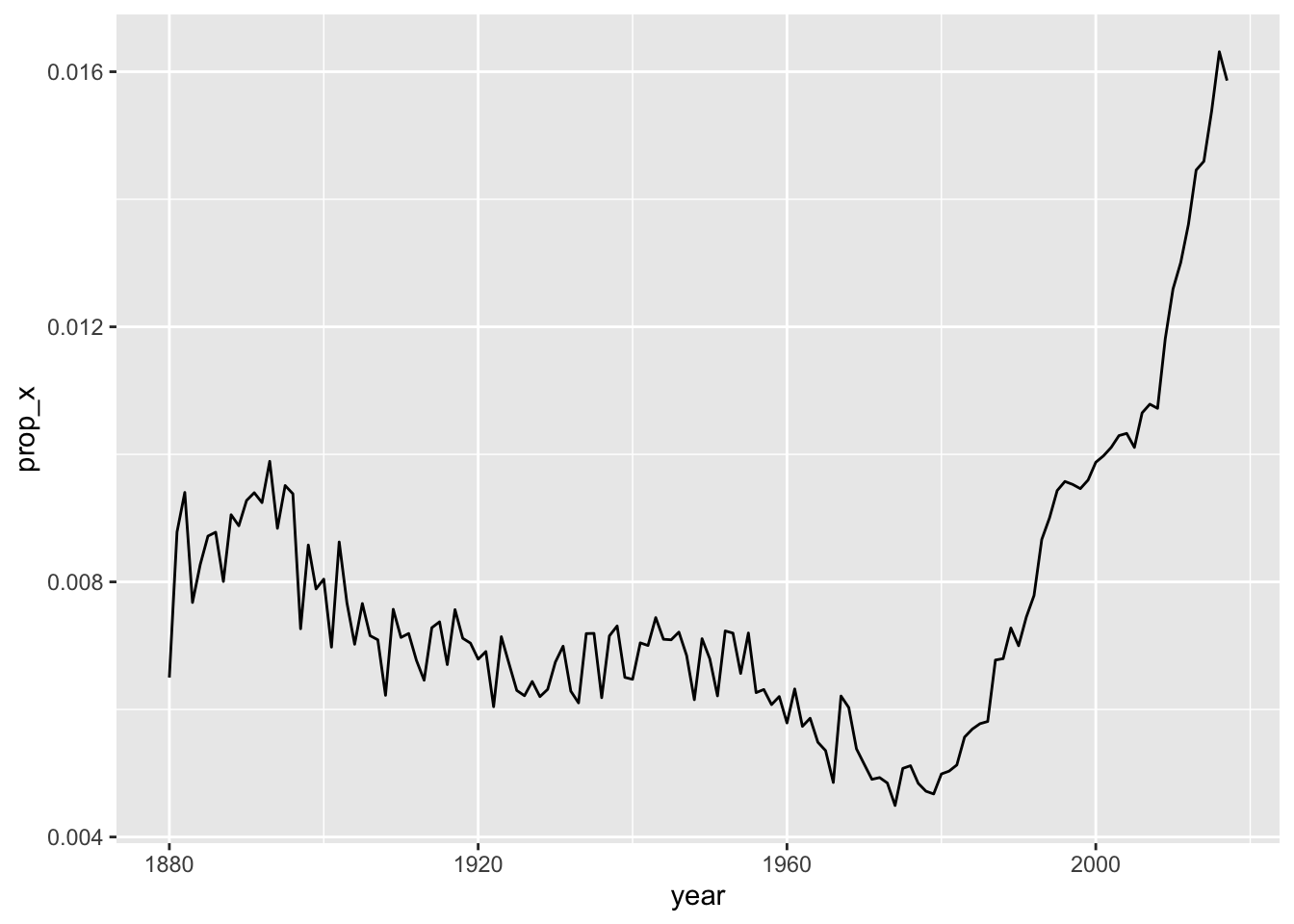
There are two functions that are closely related to str_detect(): str_subset() and str_which(). str_subset() returns a character vector containing only the strings that match. str_which() returns an integer vector giving the positions of the strings that match.
The following stack exchange suggests this solution:
# find all fruits that don't have an e
str_subset(fruit,"^((?!e).)*$") [1] "apricot" "avocado" "banana" "blackcurrant" "coconut"
[6] "currant" "damson" "dragonfruit" "durian" "fig"
[11] "guava" "jackfruit" "jambul" "kiwi fruit" "kumquat"
[16] "loquat" "mango" "nut" "papaya" "passionfruit"
[21] "physalis" "plum" "raisin" "rambutan" "satsuma"
[26] "star fruit" "tamarillo" "ugli fruit" 
str_count(): rather than a true or false, it tells you how many matches there are in each string.
x <- c("apple", "banana", "pear")
str_count(x, "p")[1] 2 0 1It’s natural to use str_count() with mutate(). The following example uses str_count() with character classes to count the number of vowels and consonants in each name.
babynames |>
count(name) |>
mutate(
vowels = str_count(name, "[aeiou]"),
consonants = str_count(name, "[^aeiou]")
)# A tibble: 97,310 × 4
name n vowels consonants
<chr> <int> <int> <int>
1 Aaban 10 2 3
2 Aabha 5 2 3
3 Aabid 2 2 3
4 Aabir 1 2 3
5 Aabriella 5 4 5
6 Aada 1 2 2
7 Aadam 26 2 3
8 Aadan 11 2 3
9 Aadarsh 17 2 5
10 Aaden 18 2 3
# ℹ 97,300 more rows3 fixes to the issue above
Add the upper case vowels to the character class: str_count(name, “[aeiouAEIOU]”).
Tell the regular expression to ignore case: str_count(name, regex(“[aeiou]”, ignore_case = TRUE)).
Use str_to_lower() to convert the names to lower case: str_count(str_to_lower(name), “[aeiou]”).
Choose one and resolove the issue above.
As well as detecting and counting matches, we can also modify them with str_replace() and str_replace_all(). str_replace() replaces the first match, and as the name suggests, str_replace_all() replaces all matches.
x <- c("apple", "pear", "banana")
str_replace_all(x, "[aeiou]", "-")[1] "-ppl-" "p--r" "b-n-n-"df <- tribble(
~str,
"<Sheryl>-F_34",
"<Kisha>-F_45",
"<Brandon>-N_33",
"<Sharon>-F_38",
"<Penny>-F_58",
"<Justin>-M_41",
"<Patricia>-F_84",
)To extract this data using separate_wider_regex() we just need to construct a sequence of regular expressions that match each piece. If we want the contents of that piece to appear in the output, we give it a name:
df |>
separate_wider_regex(
str,
patterns = c(
"<",
name = "[A-Za-z]+",
">-",
gender = ".",
"_",
age = "[0-9]+"
)
)# A tibble: 7 × 3
name gender age
<chr> <chr> <chr>
1 Sheryl F 34
2 Kisha F 45
3 Brandon N 33
4 Sharon F 38
5 Penny F 58
6 Justin M 41
7 Patricia F 84 Practice from the text
The following pattern finds all fruits that have a repeated pair of letters:
str_view(fruit, "(..)\\1") [4] │ b<anan>a
[20] │ <coco>nut
[22] │ <cucu>mber
[41] │ <juju>be
[56] │ <papa>ya
[73] │ s<alal> berryAnd this one finds all words that start and end with the same pair of letters:
str_view(words, "^(..).*\\1$")[152] │ <church>
[217] │ <decide>
[617] │ <photograph>
[699] │ <require>
[739] │ <sense># more intuitive way to define a weird string
s <- r"{"'\?}"