exercises with babynames and regular expressions
Code
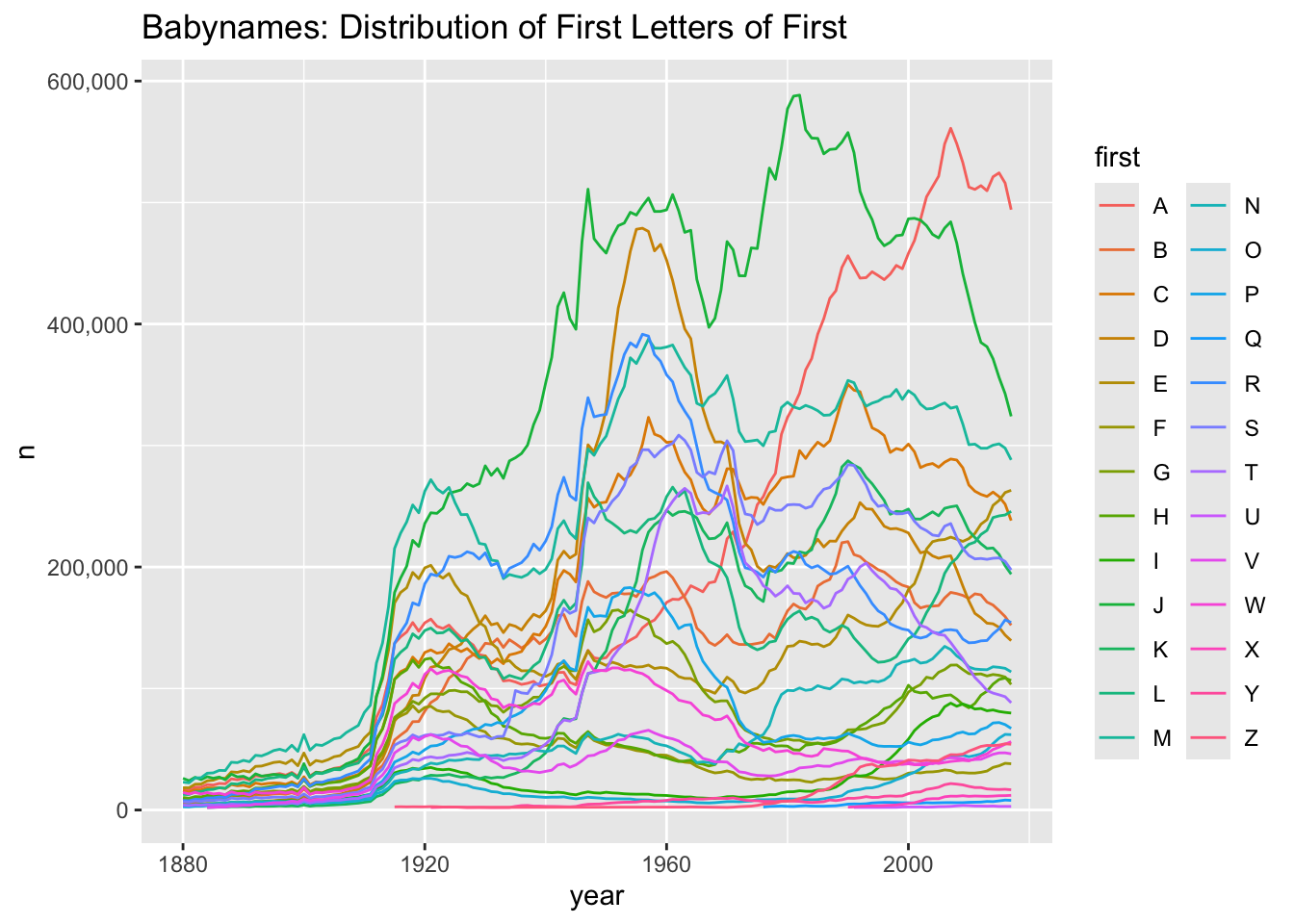
library (babynames)library (tidyverse)library (scales)|> mutate (first = str_sub (name, 1 , 1 ),last = str_sub (name, - 1 , - 1 )|> count (year, first, wt = n, sort = TRUE ) |> filter (n > 2e+03 ) |> ggplot (aes (x = year, y = n, color = first, group = first)) + geom_line () + scale_y_continuous (labels = label_comma ()) + labs (title= "Babynames: Distribution of First Letters of First" )
Code
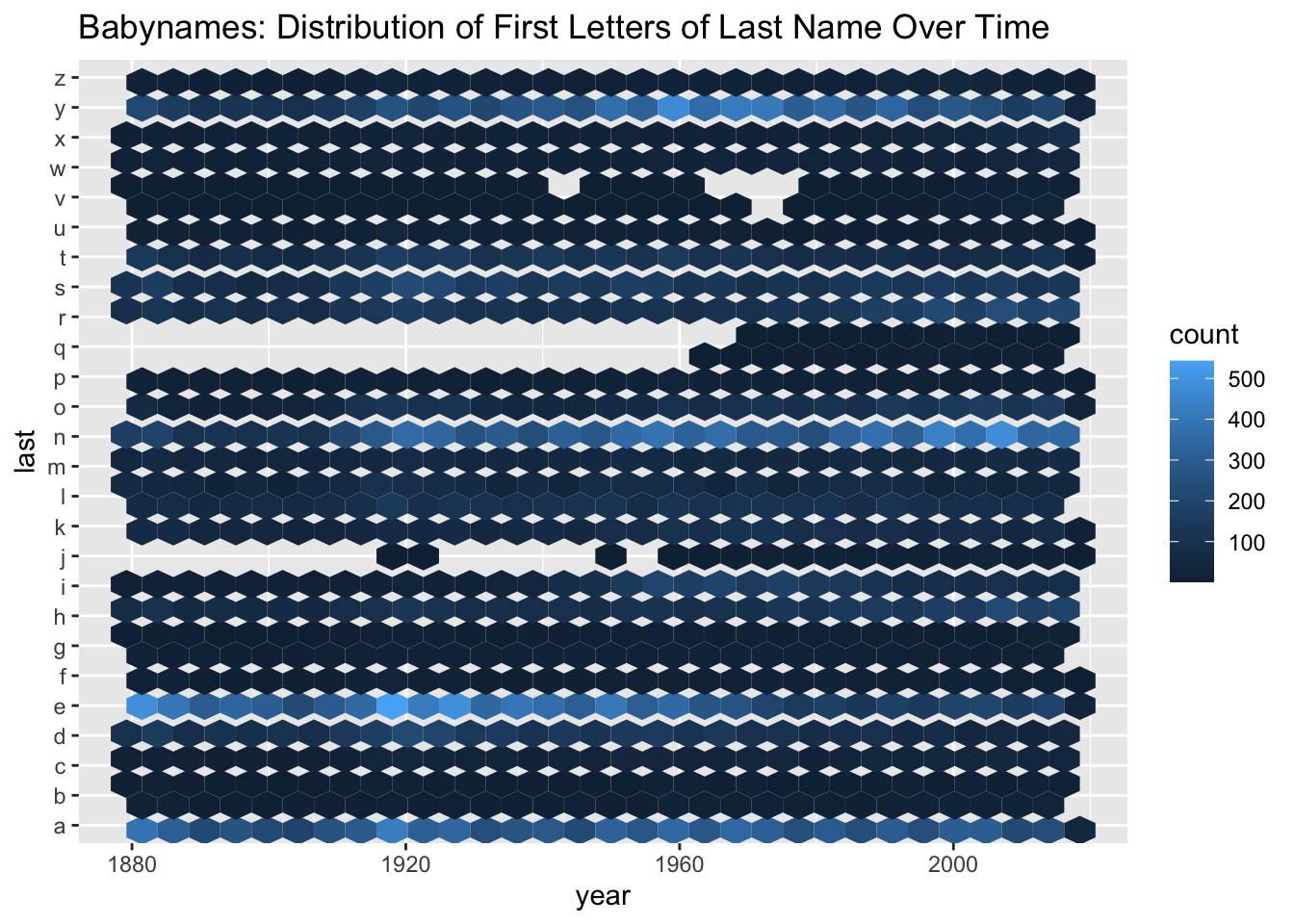
|> mutate (first = str_sub (name, 1 , 1 ),last = str_sub (name, - 1 , - 1 )|> group_by (last, wt = n) |> mutate (r = row_number ()) |> slice_head (n = 2 ) |> ggplot (aes (x = year, y = last)) + geom_hex () + labs (title= "Babynames: Distribution of First Letters of Last Name Over Time" )
What baby name has the most vowels?
Code
|> mutate (vowels = str_count (name, "[^aeiouAEIOU]" ), .keep = "used" ) |> arrange (- vowels)
# A tibble: 1,924,665 × 2
name vowels
<chr> <int>
1 Christophermich 11
2 Johnchristopher 11
3 Christophermich 11
4 Christopherjohn 11
5 Christopherjohn 11
6 Christopherjohn 11
7 Christophermich 11
8 Christopherjohn 11
9 Johnchristopher 11
10 Johnchristopher 11
# ℹ 1,924,655 more rows
What name has the highest proportion of vowels? (Hint: what is the denominator?)
Code
|> mutate (vowels = str_count (name, "[^aeiouAEIOU]" ), length = str_length (name),prop = vowels/ length,.keep = "used" ) |> arrange (- vowels, - length, prop)
# A tibble: 1,924,665 × 4
name prop vowels length
<chr> <dbl> <int> <int>
1 Christophermich 0.733 11 15
2 Johnchristopher 0.733 11 15
3 Christophermich 0.733 11 15
4 Christopherjohn 0.733 11 15
5 Christopherjohn 0.733 11 15
6 Christopherjohn 0.733 11 15
7 Christophermich 0.733 11 15
8 Christopherjohn 0.733 11 15
9 Johnchristopher 0.733 11 15
10 Johnchristopher 0.733 11 15
# ℹ 1,924,655 more rows
Replace all forward slashes in “a/b/c/d/e” with backslashes.
Code
<- str_replace_all ("a/b/c/d/e" ,"/" ," \\\\ " )print (s)
Code
Puzzle
What happens if you attempt to undo the transformation by replacing all backslashes with forward slashes? (We’ll discuss the problem very soon.)
Code
str_replace_all (s," \\\\ " ,"/" )
Implement a simple version of str_to_lower() using str_replace_all().
Code
str_replace_all ("JAY ENJOYS ISLANDS OF UBER" ,"[A-Z]" ,tolower)
[1] "jay enjoys islands of uber"
Create a regular expression that will match telephone numbers.
Code
<- "423-687-4291" str_view (a,"[0-9]?+- \\ d+- \\ d+- \\ d+" )
How would you match the literal string “’? How about”\(^\) “?
Explain why each of these patterns don’t match a : “",”\“,”\".
Given the corpus of common words in stringr::words, create regular expressions that find all words that:
Start with “y”.
Don’t start with “y”.
End with “x”.
Are exactly three letters long. (Don’t cheat by using str_length()!)
Have seven letters or more.
Contain a vowel-consonant pair.
Contain at least two vowel-consonant pairs in a row.
Only consist of repeated vowel-consonant pairs.
Write a function that mixes up words into a bad poem.
Code
# so silly <- tibble (words)<- {}<- function (.x, .y){for (i in c (1 : .y)){<- slice_sample (w,n= .x) |> pull () |> str_flatten_comma () |> str_replace_all ("," ," " ) <- str_c (a[i]," \\ n" )return (str_view (a))