library(tidyverse)
source("~/Google Drive/Teaching/DAT309/Week3/load_ATUS_data.R")Introduction to Pivoting
Re-shaping data to make analysis easier
Brief introduction w/ ATUS data
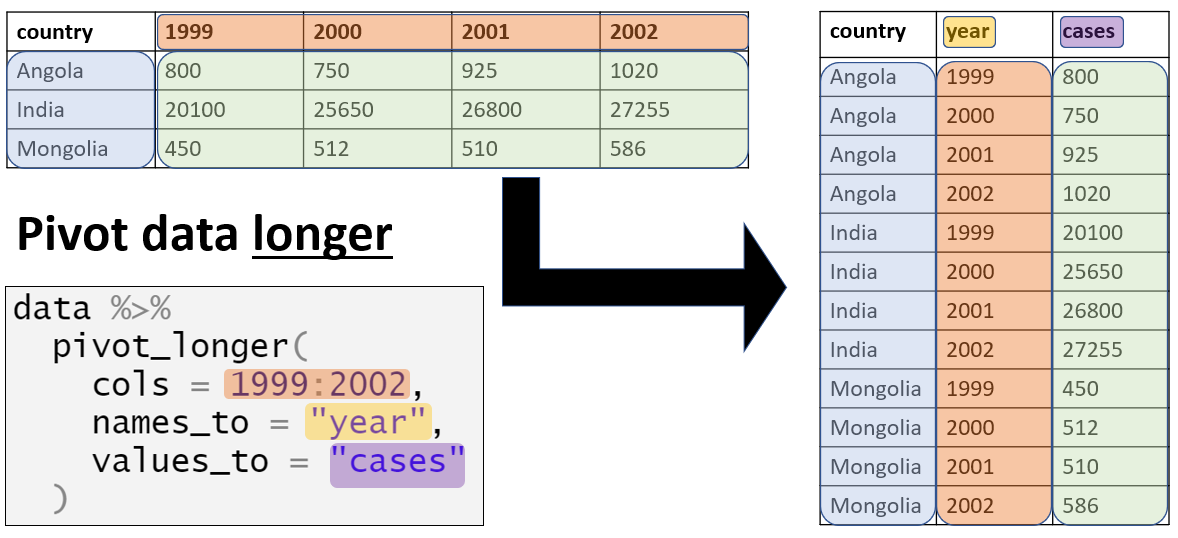
In the figure below, the data is reshaped, or made longer.
- Notice that some columns (the first) gain repeated entries.
- Also, notice that some variable names become entries in a new column.
- Also, the old entries that are spread out in rectangular form are sent to a new column.
 For more: link
For more: link
Pivoting is often used to tidy data, i.e., make it look like this:

But often data is gathered in a way that is convenient for the data collector, not the data analyst.
Example
# # # # # # # # # # # # # # # # # # # # # # # #
#
# Assumption: df is the ATUS data after clean_names
#
# Tip: use only the data you need
d <- select(df,starts_with("act"),sex,age)
# Another tip: make a new variable that keeps track of row numbers
d <- d |> mutate(row_id = row_number(age))
print(d)# A tibble: 868,270 × 6
act_social act_sports act_work sex age row_id
<dbl> <dbl> <dbl> <int+lbl> <dbl+lbl> <int>
1 0 0 910 2 [Female] 30 136179
2 0 0 910 2 [Female] 30 136180
3 0 0 910 2 [Female] 30 136181
4 0 0 910 2 [Female] 30 136182
5 0 0 910 2 [Female] 30 136183
6 0 0 910 2 [Female] 30 136184
7 0 0 910 2 [Female] 30 136185
8 0 0 910 2 [Female] 30 136186
9 0 0 910 2 [Female] 30 136187
10 0 0 910 2 [Female] 30 136188
# ℹ 868,260 more rowsStack the three minute-per-activity variables into one variable of minutes and one variable of activity type.
d_pivoted <- d |> pivot_longer(
starts_with("act_"),
names_to = "activity",
values_to = "minutes")Group the pivoted data by sex & find the total minutes on each activity for each sex
d_grouped <- group_by(d_pivoted,sex,activity) |>
summarize(min = sum(minutes, na.rm = TRUE))Make a (stacked) bar chart colored by sex, whose height tracks the number of minutes
for each activity.
d_grouped |> ggplot(
aes(x=activity, y = min, fill = as_factor(sex))) +
geom_bar(stat = "identity")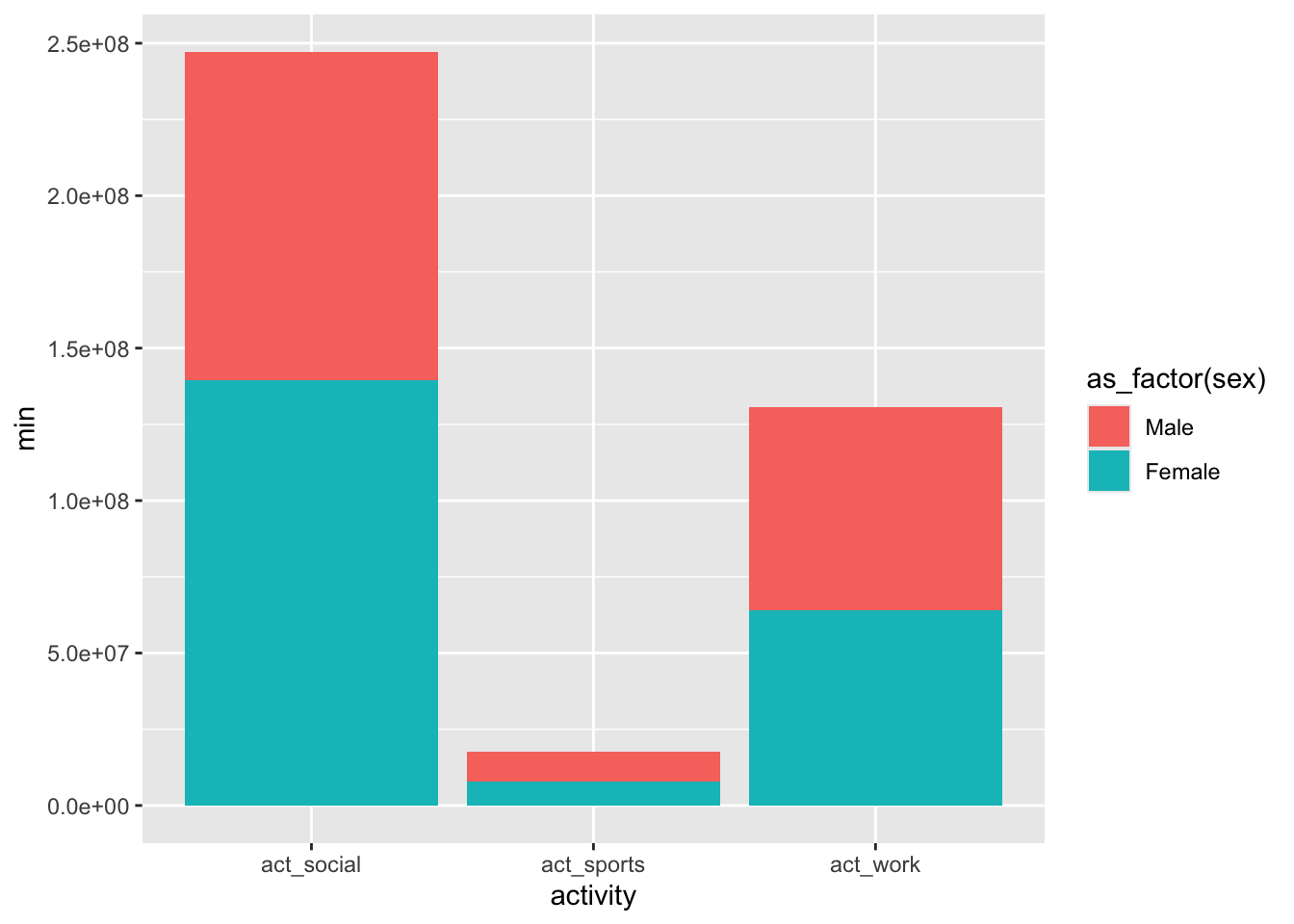
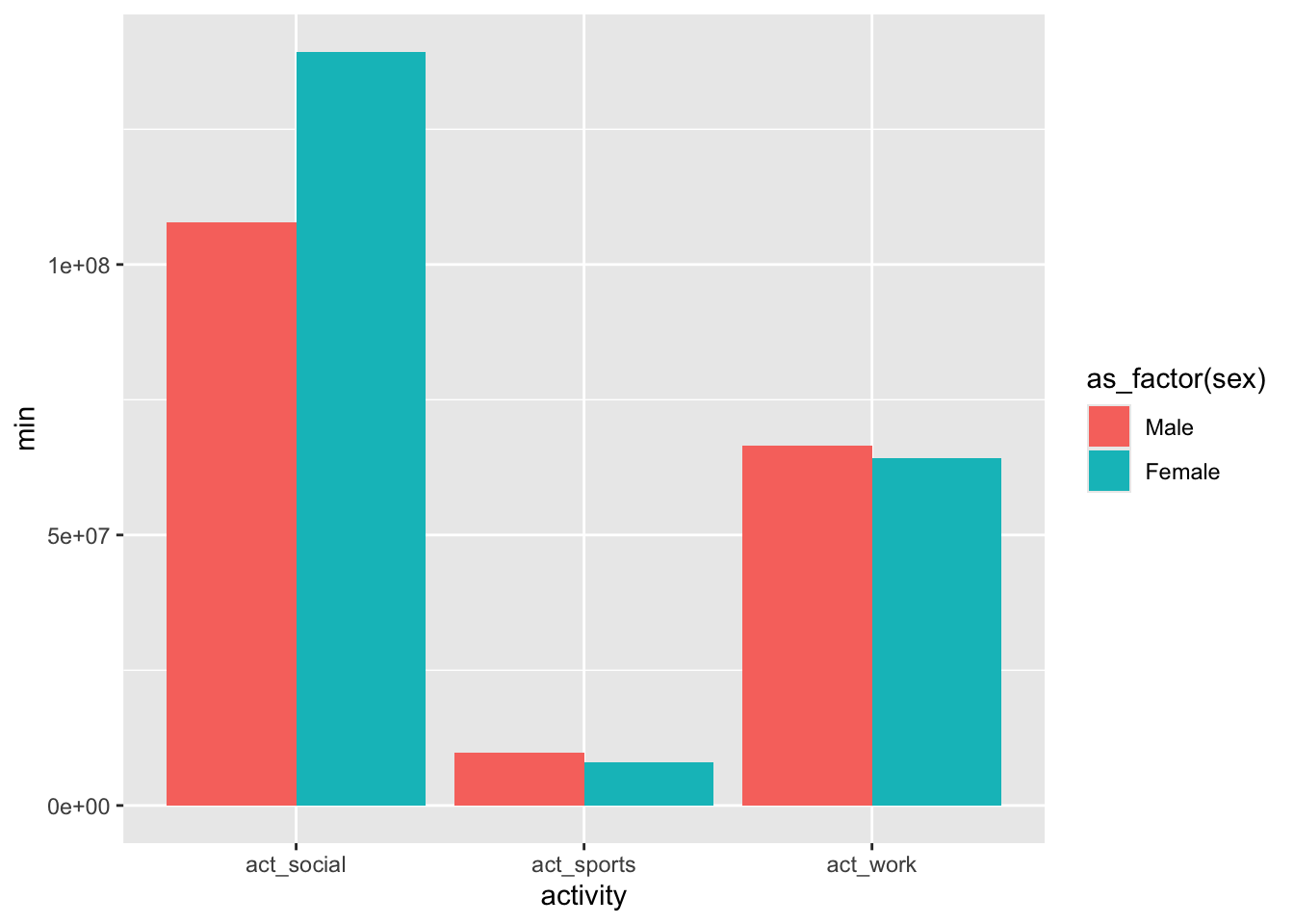
Repeat the plot above but with the bars not stacked.
d_grouped |> ggplot(aes(x=activity, y = min, fill = as_factor(sex))) + geom_bar(stat = "identity", position = "dodge")