3*4 - 5[1] 72*4^2 - 3[1] 29After you have downloaded R and RStudio (or maybe Positron) open RStudio (or maybe Positron) and play around with the software. RStudio has been the default IDE (Integrated Developer Environment) for R for many years.
Quite recently, Positron has emerged as viable IDE for R. It is similar to VSCode, and is designed as an IDE for Data Science, focusing on Python & R. It is so new however, that not all features may work. However, if you already use VSCode and Python, you might try Positron. For the time being, I will stick to RStudio.
RStudio has four main panes, the Source Editor, the Workspace Browser, the Plots, and the Console - each with various tabs. Learn more here.
Try some calculations in the console. While you’re in the console, browse the other tabs.
3*4 - 5[1] 72*4^2 - 3[1] 29Next, the function c() stands for collection and returns a collection, or list. Make several collections, varying the kinds of elements it contains. What do you learn about the behavior?
x <- c(1:25)
x^2 [1] 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 256 289 324 361
[20] 400 441 484 529 576 625last_names <- c("phillips",1:5,"lebowski")It won’t come up as often, but you could also use ‘list()’, and access like this:
# Creating a list with named components
my_list <- list(name = "Alice", age = 30, scores = c(85, 92, 78))
my_list$name[1] "Alice"my_list$scores[1] 85 92 78Many data sets and much of the functionality of R exists as packages. The code below downloads the package tidyverse from CRAN. See Section 1.4.3 of the text.
install.packages("tidyverse")The step above merely downloads the package to your machine. It does not load it in R. To use the package you check it out from the library as follows. This loads many functions and datasets.
library(tidyverse)Warning: package 'purrr' was built under R version 4.5.1── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsVisit section 1.4.4 for details.
Data is everywhere - you’re encouraged to find data on your own. But to get started we’ll use some of the many datasets that are available as packages. To see a list of datasets available in base R
# see a list of data
# some are actual datasets from scientific studies
# some are synthetic data used for training algorithms, academic study, etc.
data()This one is from a scientific study on penguins. It’s also contained in the tidyverse package.
Attaching package: 'palmerpenguins'The following objects are masked from 'package:datasets':
penguins, penguins_rawTo examine what is in this package you can use help as shown below.
help(package="palmerpenguins")So now you see penguins is a data.frame inside this package. You can explore it in a number of ways. You can type View(penguins) to view the data in RStudio. You just type penguins, or you can look a summary of the data with summary(penguins). To see just the beginning of penguins do this:
head(penguins)# A tibble: 6 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
# ℹ 2 more variables: sex <fct>, year <int>We have data about the species Adelie and its bill length 39.1 mm, among many other things. We’ll learn how to make all kinds of graphics from datasets like this. One easy thing we can do is compare male and female bill lengths as below.
Notice the <- symbol is an assignment of the right side to the left. It is to be used to assignment, where = is used as options to functions. The <- expression can be keyed in RStudio as option - in Mac or alt - in Windows.
a <- c(1:5)In the syntax below, penguins is a data frame, (like a rectangular matrix) so we can access specific entries like this:
penguins[1,2]# A tibble: 1 × 1
island
<fct>
1 Torgersenpenguins[3,]# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 40.3 18 195 3250
# ℹ 2 more variables: sex <fct>, year <int>penguins[,1]# A tibble: 344 × 1
species
<fct>
1 Adelie
2 Adelie
3 Adelie
4 Adelie
5 Adelie
6 Adelie
7 Adelie
8 Adelie
9 Adelie
10 Adelie
# ℹ 334 more rowsThe |> is the pipe which sends the left side (data, output of a function) to the right side (the right side is always a function, note the syntax of the right side sum().
c(1:5) |> sum()[1] 15The usage of the pipe may seem weird at first, but it’s ubiquitous so get used to using |>. Your code will be more readable and concise.
Here we use the pipe with to round a set of numbers
# make 5 random numbers
a <- 10*rnorm(5)
# two ways to round them
round(a)[1] 11 14 2 -12 10a |> round()[1] 11 14 2 -12 10# notice that the first parameter to round() is a data frame and the second
# is digits (how many decimal places to keep)
# the pipe always sends its data to the first parameter of the function
a |> round(digits = 2)[1] 10.97 13.50 1.58 -11.86 9.82# here's a list of numbers with some outliers
a <- c(-100, 0:10, 20)
# the mean
a |> mean()[1] -1.923077# again, the pipe sends data to the first argument of the function
# to remove the outliers from the ends we can trim
a |> mean(trim = .1)[1] 5The ggplot function is the main plotting tools we’ll use. Let’s see how the pipe |> is used in the context of ggplot(). The next two snippets are equivalent.
In the syntax of ggplot you notice that its first argument is a data frame, (this is similar to most functions) but in the code below it only accepts the aes() argument. This is because what precedes the pipe always goes into the first argument of what follows. We’ll learn this in detail later.
penguins_complete <- penguins[complete.cases(penguins),]
ggplot(penguins_complete,aes(x = body_mass_g,y = bill_length_mm, color = sex)) +
geom_point()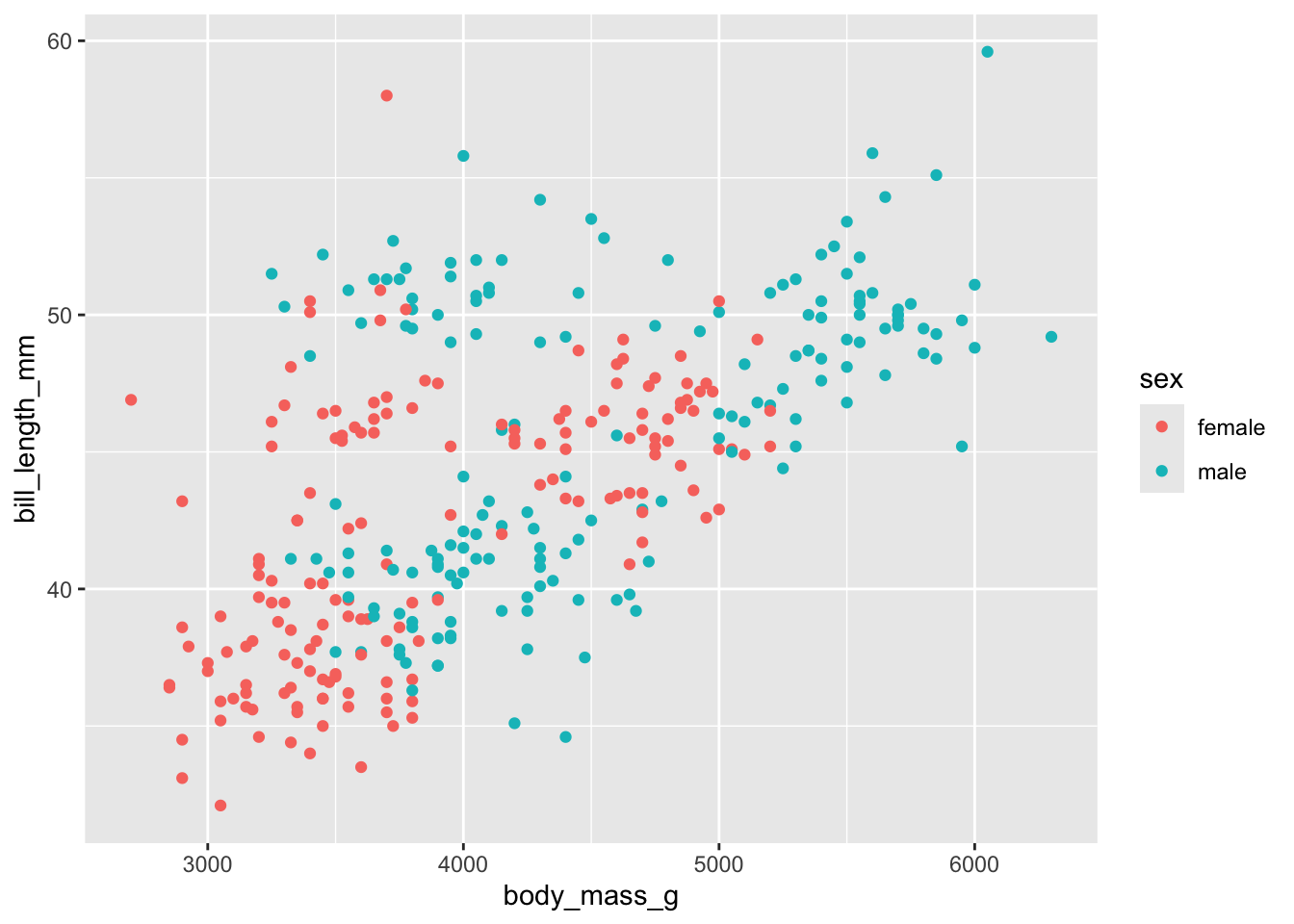
is equivalent to
penguins_complete <- penguins[complete.cases(penguins),]
penguins_complete |>
ggplot(aes(x = body_mass_g,y = bill_length_mm, color = sex)) +
geom_point()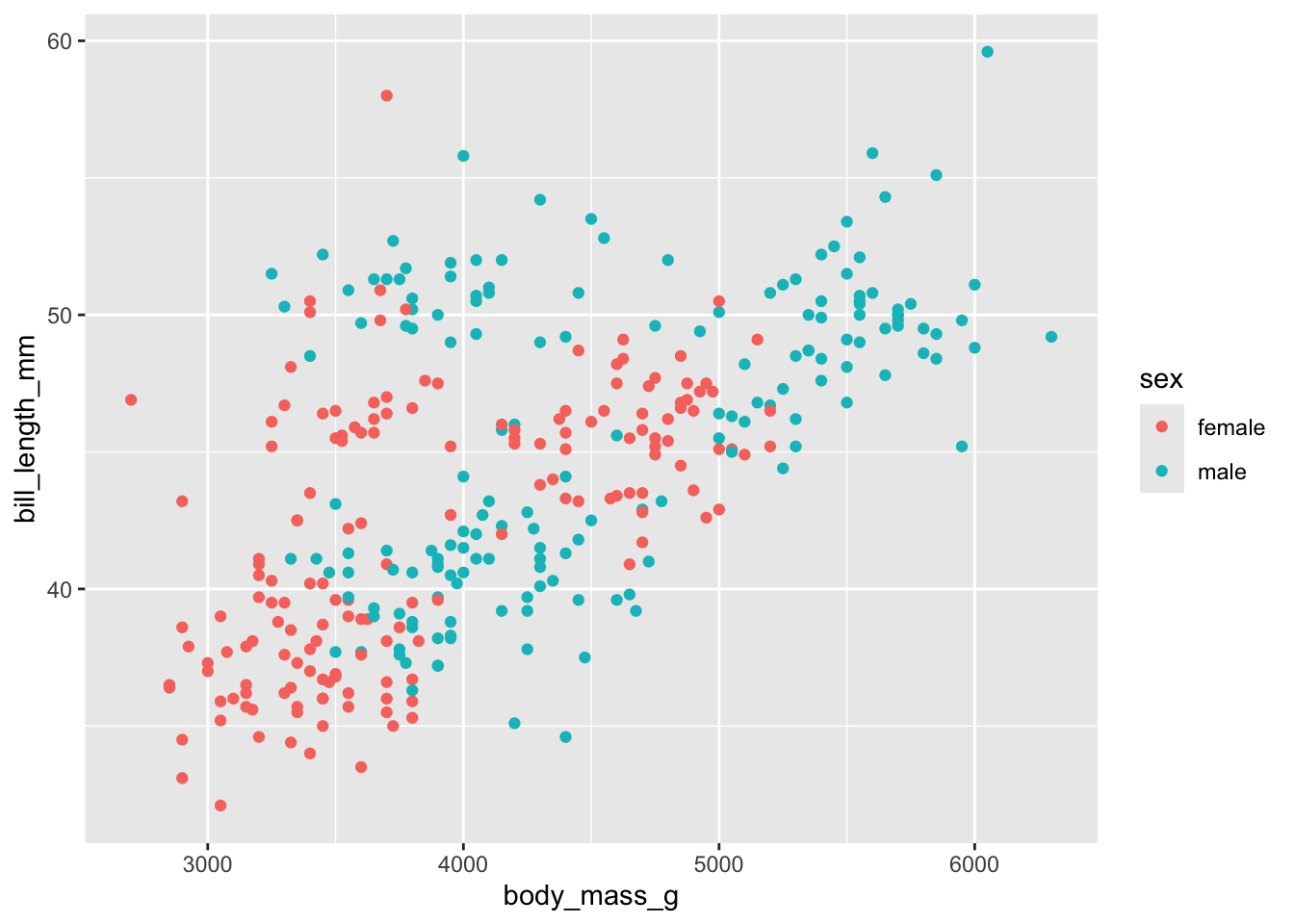
The following datasets come with the tidyverse package. Choose one and create some kind of plot from it. (Datasets: midwest, USArrests, cars). Alternately, run the following to see a big list of data that is available within R.
# This creates a file in the editor of datasets.
# Some are clean and easy to use, some are dirty by design.
data()See https://jonpage.github.io/r-course/intro.html for inspiration. Note the syntax to refer to a specific variable penguins$bill_length_mm.
Export the plot as an image and upload to your Samba Share folder.