library(tidyverse)
library(babynames)Working with Strings
using dplyr
Creating strings
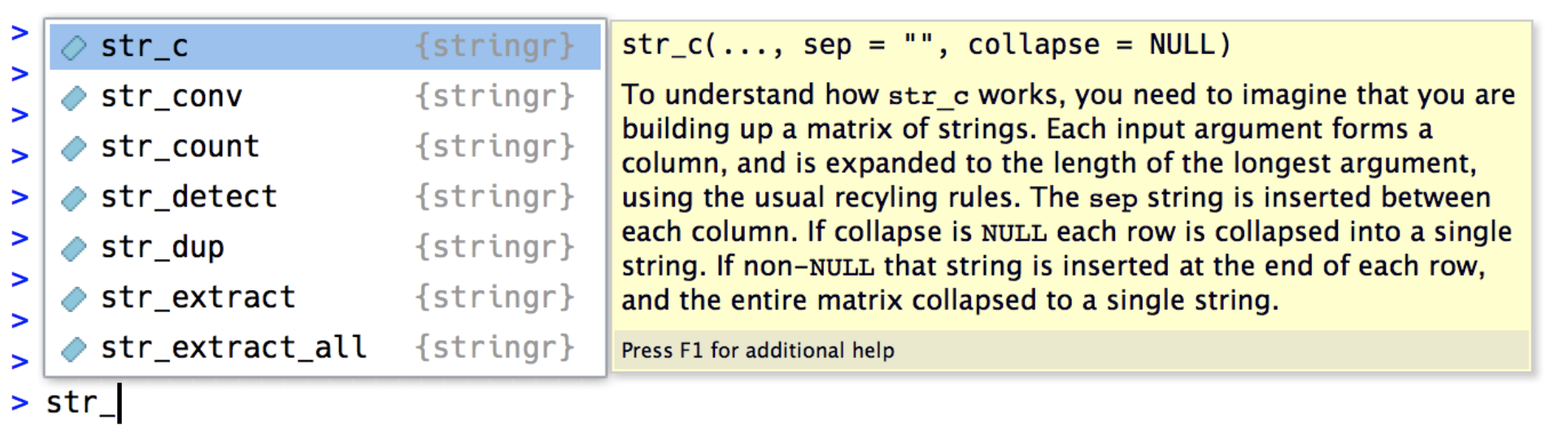
Don’t mix quote types:
string1 <- "This is a string"
string2 <- 'If I want to include a "quote" inside a string, I use single quotes'Escapes
Special characters are created with a backslash \. For example, to include quotes or a backslash inside a string, you need to escape them:
double_quote <- "\"" # or '"'
single_quote <- '\'' # or "'"
backslash <- "\\"Beware that the printed representation of a string is not the same as the string itself because the printed representation shows the escapes (in other words, when you print a string, you can copy and paste the output to recreate that string). To see the raw contents of the string, use str_view():
x <- c(single_quote, double_quote, backslash)
x[1] "'" "\"" "\\"# examine the contents of a string
str_view(x)[1] │ '
[2] │ "
[3] │ \Other common special characters include \n (new line) and \t (tab). A few less common ones are below. Notice how str_view differs from print().
Also, mathematical symbols like \(\pi\) and emojis can be included using Unicode escapes: \u followed by four hexadecimal digits, or \U followed by eight hexadecimal digits - or by latex commands (package latex2exp).
x <- c("one\ntwo", "one\ttwo", "\u00b5", "\U0001f604")
x[1] "one\ntwo" "one\ttwo" "µ" "😄" str_view(x)[1] │ one
│ two
[2] │ one{\t}two
[3] │ µ
[4] │ 😄Emojis in plots (because we can)
While there is an entire package devoted to this (package: emoGG) we do this:
- Add a geom_text(label =
\\U0001f389) layer to a scatter plot to add an emoji.
Exercise
- Create a string that contains the following values:
He said "That's amazing!"
Common String Problem
You have some text you wrote that you want to combine with strings from a data frame.
For example, you might combine “Hello” with a name variable to create a greeting. We’ll do this below. First, here’s str_c.
str_c() takes any number of vectors as arguments and returns a character vector:
str_c("x", "y")[1] "xy"str_c("x", "y", "z")[1] "xyz"str_c("Hello ", c("John", "Susan"))[1] "Hello John" "Hello Susan"Use str_c with mutate.
df <- tibble(name = c("Flora", "David", "Terra", NA))
df |> mutate(greeting = str_c("Hi ", name, "!"))# A tibble: 4 × 2
name greeting
<chr> <chr>
1 Flora Hi Flora!
2 David Hi David!
3 Terra Hi Terra!
4 <NA> <NA> A more economical alternative is str_glue(). You give it a single string that has a special feature: anything inside {} will be evaluated like it’s outside of the quotes:
df |> mutate(greeting = str_glue("Hi {name}!"))# A tibble: 4 × 2
name greeting
<chr> <glue>
1 Flora Hi Flora!
2 David Hi David!
3 Terra Hi Terra!
4 <NA> Hi NA! Summaries
str_c() and str_glue() work well with mutate() because their output is the same length as their inputs. What if you want a function that works well with summarize(), i.e. something that always returns a single string? That’s the job of str_flatten(): it takes a character vector and combines each element of the vector into a single string:
str_flatten(c("x", "y", "z"))[1] "xyz"str_flatten(c("x", "y", "z"), ", ")[1] "x, y, z"str_flatten(c("x", "y", "z"), ", ", last = ", and ")[1] "x, y, and z"str_flatten() works well with summarize
df <- tribble(
~ name, ~ fruit,
"Carmen", "banana",
"Carmen", "apple",
"Marvin", "nectarine",
"Terence", "cantaloupe",
"Terence", "papaya",
"Terence", "mandarin"
)
df |>
group_by(name) |>
summarize(fruits = str_flatten(fruit, ", "))# A tibble: 3 × 2
name fruits
<chr> <chr>
1 Carmen banana, apple
2 Marvin nectarine
3 Terence cantaloupe, papaya, mandarinExtracting data from strings
It’s very common for multiple variables to be crammed together into a single string. Here’s how to extract them.
df |> separate_longer_delim(col, delim)
df |> separate_longer_position(col, width)
df |> separate_wider_delim(col, delim, names)
df |> separate_wider_position(col, widths)Separating into rows
# the number of compoennts varies from row to row
df1 <- tibble(x = c("a,b,c", "d,e", "f"))
df1 |>
separate_longer_delim(x, delim = ",")# A tibble: 6 × 1
x
<chr>
1 a
2 b
3 c
4 d
5 e
6 f To separate along fixed widths …
df2 <- tibble(x = c("1211", "1314", "21"))
df2 |>
separate_longer_position(x, width = 2)# A tibble: 5 × 1
x
<chr>
1 12
2 11
3 13
4 14
5 21 Separating into columns
Separating a string into columns tends to be most useful when there are a fixed number of components in each string, and you want to spread them into columns.
# give names to the new columns created
df3 <- tibble(x = c("a10.1.2022", "b10.2.2011", "e15.1.2015"))
df3 |>
separate_wider_delim(
x,
delim = ".",
names = c("code", "edition", "year")
)# A tibble: 3 × 3
code edition year
<chr> <chr> <chr>
1 a10 1 2022
2 b10 2 2011
3 e15 1 2015 Exercise
- What would a
NAin thenamesvector above do?
separate_wider_position() works a little differently because you typically want to specify the width of each column. So you give it a named integer vector, where the name gives the name of the new column, and the value is the number of characters it occupies.
df4 <- tibble(x = c("202215TX", "202122LA", "202325CA"))
df4 |>
separate_wider_position(
x,
widths = c(year = 4, age = 2, state = 2)
)# A tibble: 3 × 3
year age state
<chr> <chr> <chr>
1 2022 15 TX
2 2021 22 LA
3 2023 25 CA Diagnosing widening problems
See the text
Letters
str_length() tells you the number of letters in the string:
str_length(c("a", "R for data science", NA))[1] 1 18 NAYou could use this with count() to find the distribution of lengths of US babynames and then with filter() to look at the longest names, which happen to have 15 letters:
babynames |>
count(length = str_length(name), wt = n)# A tibble: 14 × 2
length n
<int> <int>
1 2 338150
2 3 8589596
3 4 48506739
4 5 87011607
5 6 90749404
6 7 72120767
7 8 25404066
8 9 11926551
9 10 1306159
10 11 2135827
11 12 16295
12 13 10845
13 14 3681
14 15 830babynames |>
filter(str_length(name) == 15) |>
count(name, wt = n, sort = TRUE)# A tibble: 34 × 2
name n
<chr> <int>
1 Franciscojavier 123
2 Christopherjohn 118
3 Johnchristopher 118
4 Christopherjame 108
5 Christophermich 52
6 Ryanchristopher 45
7 Mariadelosangel 28
8 Jonathanmichael 25
9 Christianjoseph 22
10 Christopherjose 22
# ℹ 24 more rowsSubsetting
You can extract parts of a string using str_sub(string, start, end), where start and end are the positions where the substring should start and end. The start and end arguments are inclusive, so the length of the returned string will be end - start + 1:
x <- c("Apple", "Banana", "Pear")
str_sub(x, 1, 3)[1] "App" "Ban" "Pea"Exercise
- What do negative numbers do in
str_sub()?
Here’s how to find the first and last letters of each name in babynames.
babynames |>
mutate(
first = str_sub(name, 1, 1),
last = str_sub(name, -1, -1)
)# A tibble: 1,924,665 × 7
year sex name n prop first last
<dbl> <chr> <chr> <int> <dbl> <chr> <chr>
1 1880 F Mary 7065 0.0724 M y
2 1880 F Anna 2604 0.0267 A a
3 1880 F Emma 2003 0.0205 E a
4 1880 F Elizabeth 1939 0.0199 E h
5 1880 F Minnie 1746 0.0179 M e
6 1880 F Margaret 1578 0.0162 M t
7 1880 F Ida 1472 0.0151 I a
8 1880 F Alice 1414 0.0145 A e
9 1880 F Bertha 1320 0.0135 B a
10 1880 F Sarah 1288 0.0132 S h
# ℹ 1,924,655 more rowsExercises
1.When computing the distribution of the length of babynames, why did we use wt = n?
Use
str_length()andstr_sub()to extract the middle letter from each baby name. What will you do if the string has an even number of characters?Are there any major trends in the length of babynames over time? What about the popularity of first and last letters?
Write a function that creates a new name from two names in the
babynamesdataset by gluing the two names together.